
Postgres 13 Row-Level Security Performance
September 12th, 2021I’ve recently been looking into various row-level security schemas for Postgres, and came across this excellent article benchmarking a few different architectures for row-level security. That post shows benchmarks for Postgres 10—three major versions ago.
I forked the repo (GitHub), upgraded to Postgres 13, and added a new architecture based on Carl Sverre’s comment to see what’s changed.
I ran each benchmark on a maxed 2019 16” MacBook Pro (2.4 8-core/64GB RAM), with 100 users and 10,000 total items. Notably, all of my results are significantly slower than what the original post achieved—I suspect this comes from running Postgres in Docker on MacOS, which has known disk performance issues.
RLS + ACL column
In this schema, ACLs are stored directly in columns on the secured table. Public items are handled as just another role.
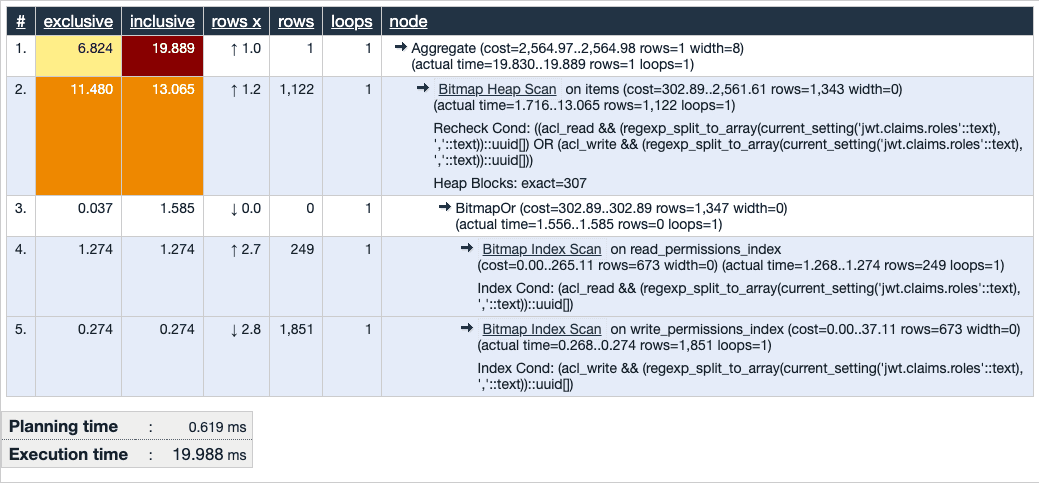
RLS + ACL table
ACLs are stored in a permissions table joining roles and items.
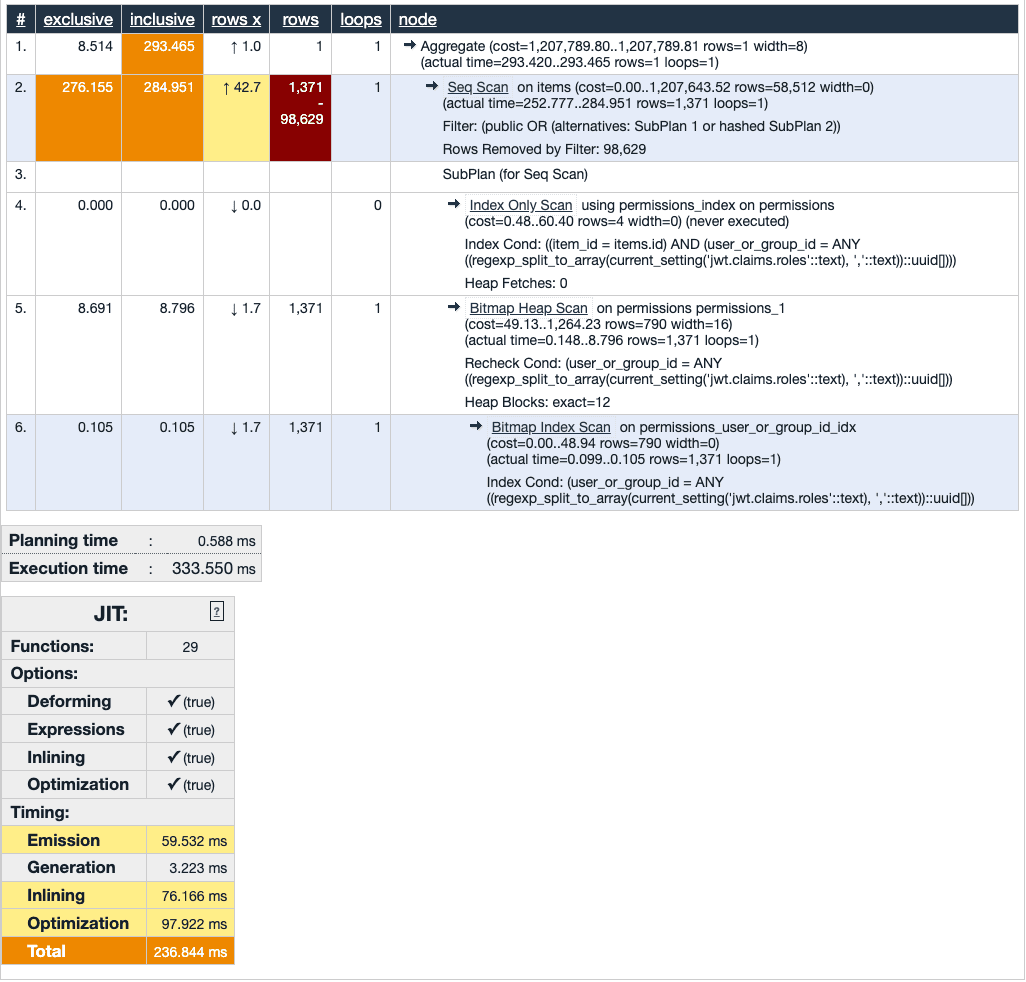
Security barrier view + ACL table
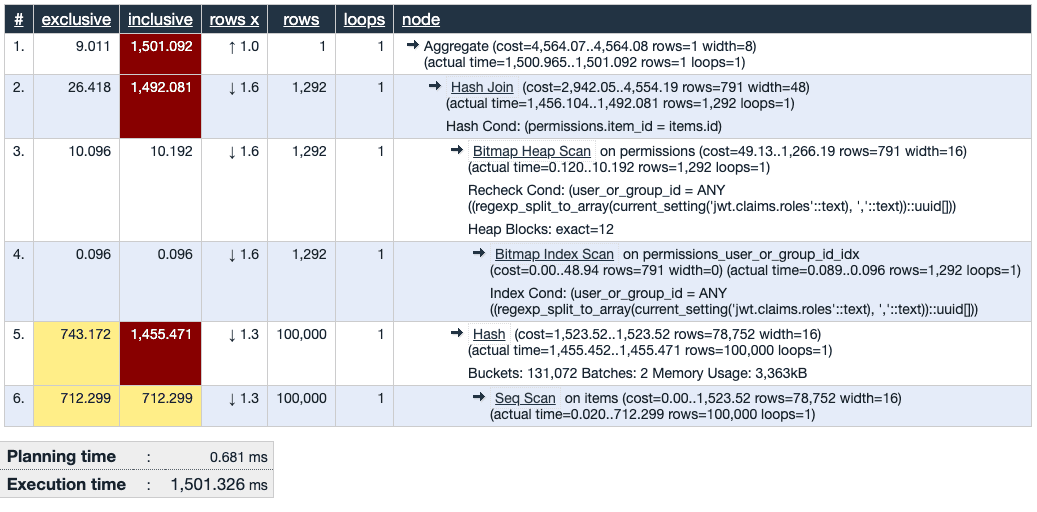
RLS + ACL table with stored functions
Carl from MemSQL proposed this architecture and claimed better performance because the query optimizer could “build a set of the object ids for the current array of subjects and leverage that during query execution.” Instead of querying across the entire permissions table in each RLS check, we can define a function query_objects(subjects, action) that returns the set of authorized items a list of subjects has access to:
create or replace function query_objects(subjects uuid[], role permission_role)
returns uuid as $$
select item_id
from permissions
where (
permissions.user_or_group_id = any(subjects) and
(role = 'read' or permissions.role = role)
)
$$
language sql;Then, our RLS policy becomes:
create policy item_owner
on items
as permissive
for all
to application_user
using (
items.public = true
or items.id = any(select query_objects from query_objects(my_roles(), 'read'))
)
with check (
items.id = any(select query_objects from query_objects(my_roles(), 'write'))
);where my_roles is simply:
create or replace function my_roles()
returns uuid[] as $$
select regexp_split_to_array(current_setting('jwt.claims.roles'), ',')::uuid[]
$$
language sql;This is a huge improvement: its performance is on par with the column-based schema!

Conclusion
It seems like the best approach may be the last one: an ACL table with a couple stored functions to help the query planner. It gives us the advantages of an ACL table (data tables don’t have metadata on them, ACL data is normalized) without the fairly large performance hits that the other methods have.